
%20(47).png?width=1380&name=Insights%20Inbox%20LinkedIn%20Newsletter%20Template%20(752%20x%20423%20px)%20(47).png "<span id=\"hs_cos_wrapper_name\" class=\"hs_cos_wrapper hs_cos_wrapper_meta_field hs_cos_wrapper_type_text\" style=\"\" data-hs-cos-general-type=\"meta_field\" data-hs-cos-type=\"text\" >Beyond the Prompt: Where LLMs End and Agentic AI Begins</span>")
Most conversations about AI collapse everything into one category, the LLMs, "ask and get answers" model, assuming all AI operates the same way and has same power to surface insights. A question gets asked, an answer is returned, and the work moves forward. That feels efficient, or satisfactory at least; and, it often is for simple inputs and tasks. However, LLMs are not capable of synthesizing insights and reliably recognizing patterns from vast swathes of data — they actually are very limited in the data they have access to, and any existing data is outdated, based on when the model was trained. And as we have all experienced in some way, LLMs are notorious for hallucinating when they don't know the answer, and presenting that as fact — a shaky, if not risky foundation for a business to rely on for crucial strategy decisions.
Large language models and agentic AI systems are often grouped together under the AI umbrella, but they operate on fundamentally different layers of the workflow, have access to vastly different data sets, and have crucial differences in analysis capabilities.
AI has already evolved, and one-size-fits all AI no longer fits businesses.
Agentic AI doesn’t just answer questions—it builds a living model of your market. It pulls from massive, hard-to-access data ecosystems—social, market, consumer, patent, competitor, news, behavioral, review, and media data—and continuously connects that with your internal data to create a full view of your business. Instead of relying on static data, it processes billions of real-time signals, analyzing not just what is happening, but why, how fast it’s evolving, and whether it’s worth acting on. It surfaces relationships LLMs miss entirely—connecting seemingly unrelated trends across categories, identifying the strength and trajectory of those trends, and even exposing whitespace by analyzing what’s not there. It detects early risks before they materialize, maps the “trend of the trend” to show what’s rising or fading, and most importantly, translates all of that into clear, business-specific action.
In LLM outputs, what looks like detailed, thoughtful analysis is often just response generation layered on top of incomplete or inconsistent inputs. The system is doing exactly what it was designed to do. It answers the question it was given, based on the information available in that moment.
It does not ensure that the information is complete, structured, or consistent across teams, timeframes, or use cases.
Most people do not notice the difference at first. The outputs read well. They align with expectations. They feel actionable.
The problems show up later, and they affect how decisions are made, communicated, and trusted across the organization.
This is where everything that looked efficient starts to feel unstable.
Understanding the difference between these two technologies is where most teams either gain leverage or quietly introduce risk into their process.
Key Takeaways
Organizations that recognize this early build alignment and move faster. Those that do not spend time reconciling conflicting answers that should have never diverged.
LLMs are extremely effective at reasoning over language. They take messy inputs and turn them into something readable, structured, and usable. They summarize, translate, reframe, and generate ideas quickly. They reduce friction in tasks that used to require time, back-and-forth, and manual effort. They respond. They do not verify. And when response generation is used as a substitute for analysis, the risk is not immediately visible, but it is already present.
They help people move faster at the beginning of a process and make it easier to get from a blank page to something workable.
In controlled contexts, they are powerful. The problem is not capability though, it’s scope. LLMs operate within the boundaries of the prompt and the data they have access to in that moment.
They do not inherently validate whether the dataset is complete or resolve conflicting inputs—not unless explicitly guided to do so. They do not ensure that their summary reflects the full picture. They merely respond. They do not verify. And this is where the LLM workflows start to break.
The moment LLMs are used for analysis, the cracks appear. Outputs begin to vary depending on:
Two people can ask similar questions and receive very different answers. Both may sound plausible, be well-written and feel actionable.
This creates a subtle but significant problem, because the system produces confidence without consistency.
For example, imagine a global marketing team is preparing a quarterly strategy update. One regional lead asks an LLM: “What are the top consumer trends in [industry] right now based on recent social and media coverage?” Another team, working in parallel, asks: “What themes are driving customer sentiment in [industry] this quarter?”
Both receive structured, well-written summaries.
Neither answer is obviously wrong, but they are certainly not aligned.
What happens if both teams move forward using their respective outputs? By the time insights reach leadership, the organization is operating on two different interpretations of the same market environment.
On a small scale, this feels like a minor inconvenience. At the organizational scale, it becomes a significant misalignment. What begins as variation in wording becomes variation in strategy. Over time, that variation turns into misalignment that is difficult to detect and harder to correct.
Agentic AI systems are designed to do more than generate responses. They manage the process that leads to those responses. This includes:
Instead of relying on a single interaction, these systems create a framework where analysis can be repeated, validated, and scaled.
For example, in Quid’s March Madness network visualization, the dataset does not appear as a single conversation. It separates into distinct clusters that reflect how attention actually organizes in the market. Several primary clusters emerge:
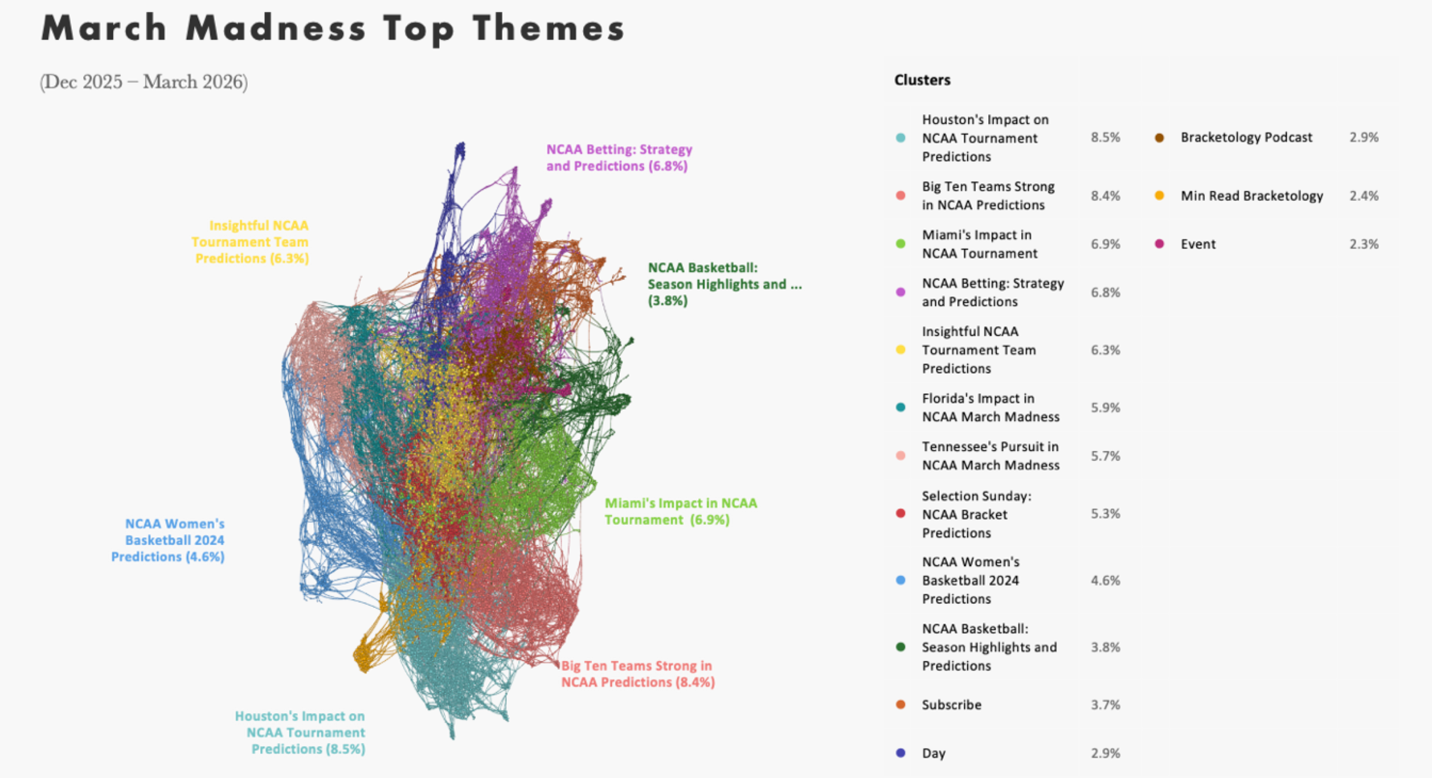
What matters is not just that these themes exist, but how they connect. The network shows:
For example, athlete-driven storytelling does not sit in isolation. It connects directly into social amplification and, in some cases, drives spikes in betting conversation. That relationship is visible in the network before it becomes obvious in summary-level reporting.
Outliers also surface early in an agentic analysis. Smaller nodes begin forming around emerging players or unexpected moments, often before they register as “trends” in traditional summaries. This is the difference between observing a conversation and modeling it.
A generated summary might tell you that “athletes and betting are key themes.” The network shows:
It shows a system of relationships and drives home the subtle but critical distinction: one system answers questions; the other ensures the answers are grounded in something stable. Without this level of structure, teams are left interpreting summaries rather than working from the same underlying system. That difference is where alignment either holds or breaks.
As decisions become more complex, the ability to trace insight back to source data becomes essential. LLM outputs typically do not provide clear data lineage, consistent methodology, or reproducible steps. They provide answers, but not accountability.
Agentic systems are built to preserve that chain, with each insight traceable to specific signals. Take Quid’s analysis of Spring Cleaning, for example:
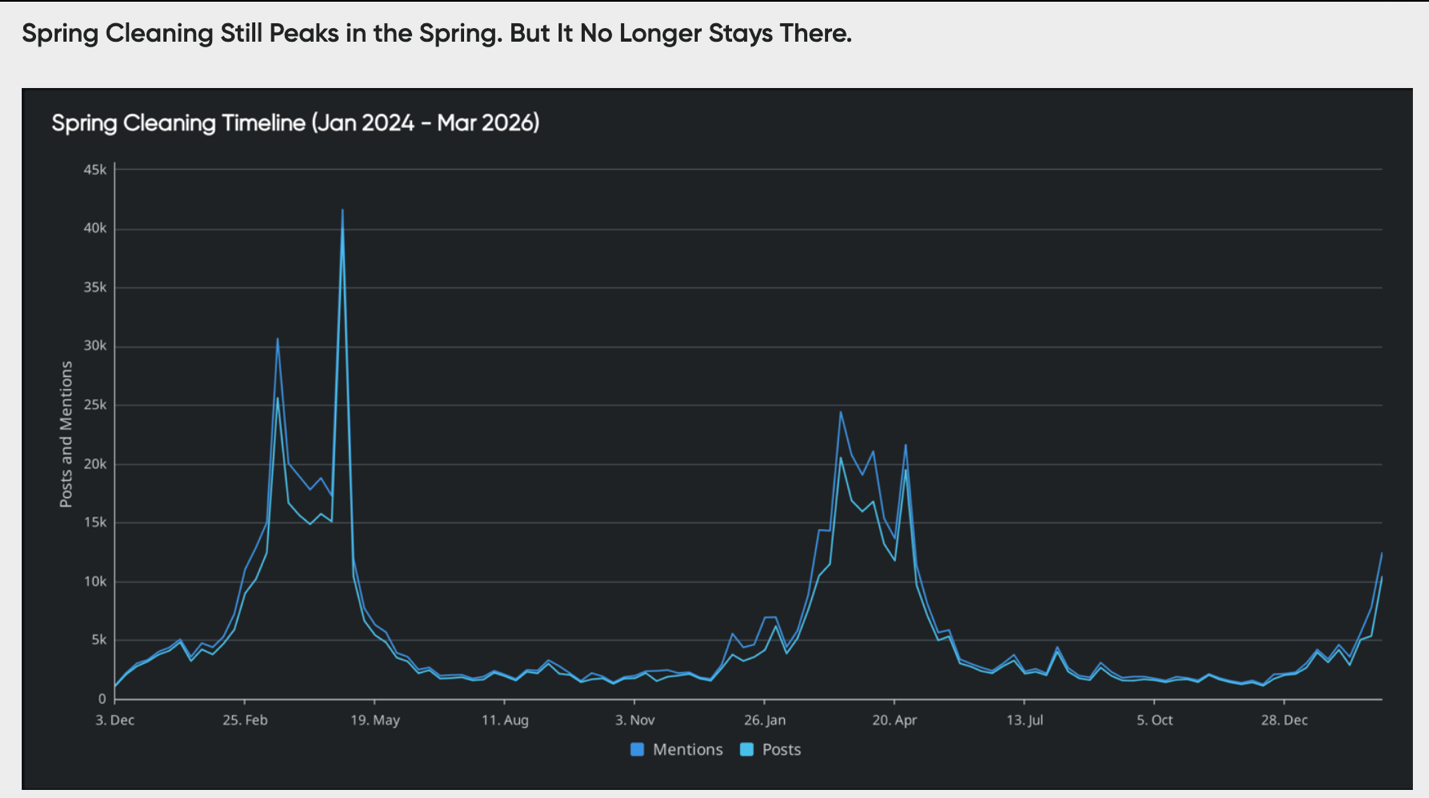
The timeline shows that conversation exists and how it behaves over time.
Each of these patterns can be traced back to underlying drivers. Media coverage, promotional cycles, and shifting consumer behavior all contribute to when and why attention increases or declines. This changes how the insight is interpreted.
A generated summary might say: “Spring cleaning is a strong seasonal trend.” The data shows something more specific:
The path from signal to conclusion is visible. This matters most when decisions carry financial risk, teams need to justify conclusions, and strategies must be defended over time. Without traceability, these nuances are flattened into generalizations. And generalizations are where strategy starts to drift from reality.
Early use of AI focused on speed, but speed is no longer the constraint. Consistency, reliability, and defensibility are now the pressure points. As organizations scale their use of AI, isolated outputs become harder to manage, inconsistencies compound across teams, and decisions require supporting structure, not just answers.
The issues outlined here rarely fail fast. They accumulate.
At first, nothing breaks, but then performance drifts, campaigns miss, and decisions take longer to justify. Confidence erodes internally.
Externally, the risks are more visible. Insights that cannot be sourced get challenged, and recommendations that cannot be explained lose credibility. In some cases, hallucinated or unverifiable outputs make their way into client-facing work.
Misunderstanding the difference between response generation and analytical infrastructure creates both inefficiencies and exposure.
LLMs and agentic systems are not competing technologies. They operate at different stages of the same process.
Used together, they are powerful. Used interchangeably, they introduce risk.
Most organizations are not failing because they are using AI. They are struggling because they are relying on tools designed for response generation to perform tasks that require structured analysis.
If your teams are working from different versions of the same market, the issue is not visibility. It is structure.
Quid helps organizations move beyond prompt-driven workflows by structuring data, modeling relationships, and making insights traceable from signal to decision.
What is the main difference between LLMs and agentic AI?
LLMs generate responses based on prompts and uploaded training data. LLMs don't continue to learn and synthesize data without being prompted, don't have access to large data sources, and are not real-time, often resulting in hallucinations. LLMs thrive with task execution, but actual analysis requires more. Agentic AI systems manage data ingestion, structuring, analysis, and execution across workflows and are able to synthesize this data to identify complex patterns, insights, and trends, automatically, in real time.
Can LLMs be used for analysis?
They can assist with interpretation of explicitly provided data, or training data relevant only up to the date the LLM was trained, but without access to real-time, structured data and powerful analysis and synthesizing capabilities, outputs can be hallucinated, outdated, or irrelevant.
Why does variability in LLM outputs matter?
Inconsistent outputs can lead to misalignment across teams and unreliable conclusions, especially in decision-making contexts.
What makes agentic AI more reliable for decision-making?
Agentic systems provide structured, repeatable processes with traceable data sources, making insights easier to validate and defend.
Do LLMs and agentic AI replace each other?
No. They serve different roles. LLMs support reasoning and generation, while agentic systems provide the infrastructure needed for consistent analysis and decision support.